one decoder block · word tokens · sparse attention
attoGPT Explorer
Edit the context, choose any token as the prediction point, and inspect exactly which previous tokens each attention head uses for the next-token prediction.
What am I looking at? architecture, training, and how to read the display
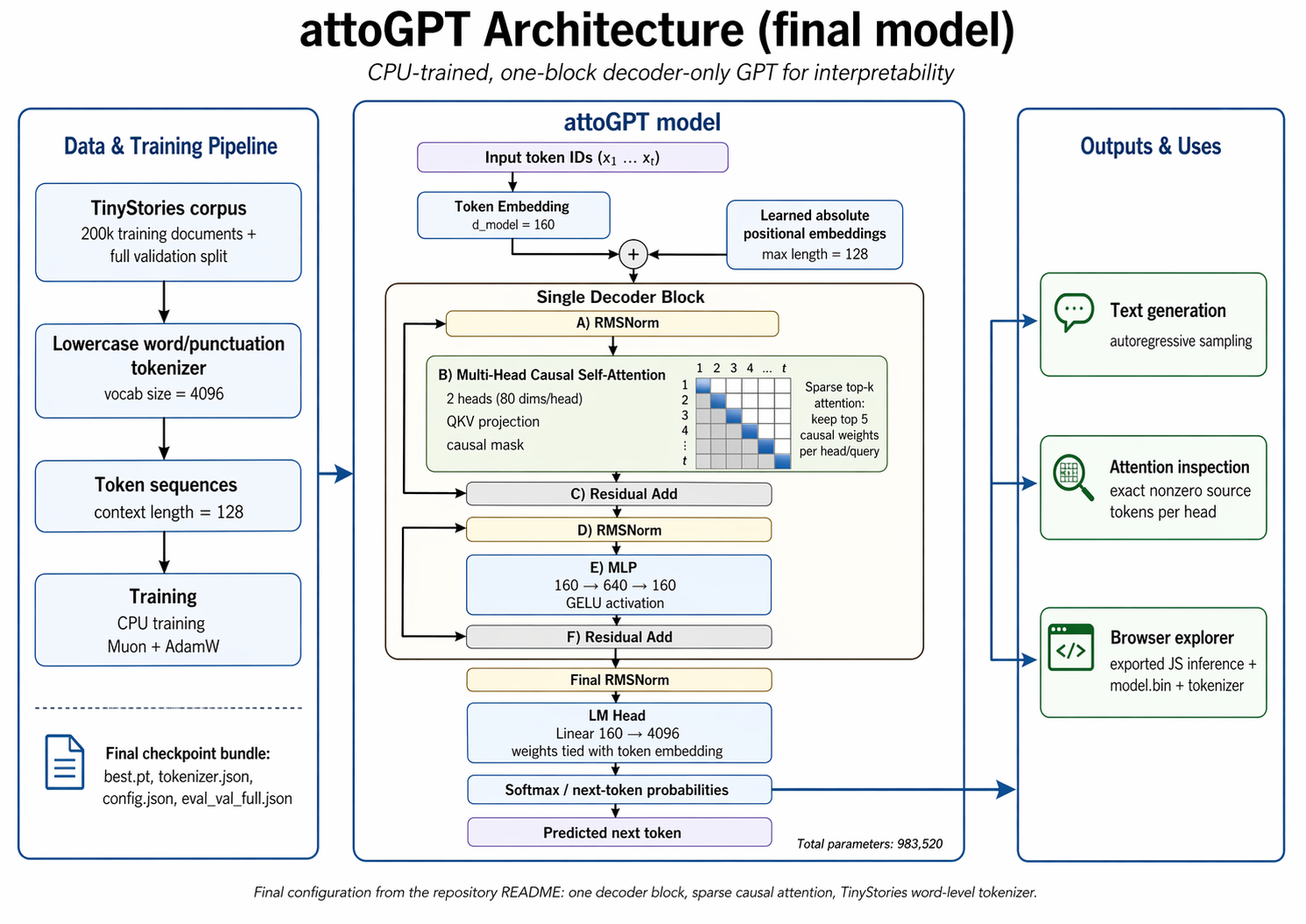
The Model
This page runs a complete GPT-style language model directly in your browser. It is deliberately tiny: one decoder block, 983,520 parameters, a 4096-token word vocabulary, two attention heads, and a context window of 128 tokens.
The model reads a sequence of tokens and predicts the next token. A token is usually a lowercase word, comma, period, question mark, or exclamation mark. Unknown words are not free-form; they must be replaced with nearby vocabulary entries.
The Forward Pass
Each token is turned into a 160-number vector, then a learned position vector is added so the model knows where the token sits in the sentence. The single decoder block has two parts: causal self-attention and an MLP.
Attention decides which earlier tokens to copy information from. The MLP then transforms the result into features useful for predicting the next token. Finally, the model compares the last vector with every vocabulary entry and produces a probability distribution.
Why The Bars Matter
Normal attention spreads small weights over many previous tokens, which is hard to explain visually. This model uses top-k sparse attention: for every prediction, each head keeps only its five strongest causal attention links and sets all other links to zero.
The colored bars under a token show how much the selected prediction position is attending to that token. Orange is head 0; teal is head 1. If a bar is absent, that head did not use that token at all for the current prediction.
Training
The model was trained from scratch on TinyStories: simple English short stories generated for training and evaluating very small language models. Text was lowercased and simplified to words plus basic punctuation.
The final run used 200,000 training stories, a full validation split, 12,000 CPU optimization steps, Muon for hidden weight matrices, and AdamW for embeddings and normalization weights. Full validation is 0.8338 bits per byte.
initializing...
GitHub repo